

Why Connectors Built on Data Sharing Still Require Data Copy

If you follow the space, you’ve likely noticed the buzz of excitement around “zero copy” data sharing and its promises to end duplication, reduce costs, and make concerns from security and governance teams a thing of the past.
It’s no wonder. Enterprises invested millions in cloud technologies — such as data lakes to centralize customer data — recognizing that technology, security and controls are mature enough to overcome early concerns. Even highly regulated industries such as financial services are planning significant efforts to increase cloud adoption.
And as millions are poured into these cloud migration and data centralization efforts, a fear rose among IT teams: in order to keep data in sync with tools used by business teams, will I need to recreate data pipelines and keep a copy of data in every business application too?
“Zero copy” data sharing was said to be the solution to the problem. But this capability is yet another broken promise — and these data sharing connectors still require data to be copied.
But here’s the good news: there is a solution to share accurate data across your entire tech stack and remove the need for creating data copies. Let’s dig in.
Why Connectors Built on Data Sharing Capabilities Still Require Data Copy
The (New) Imperative to Reduce Data Copies
A data pipeline is a set of processes and data management allowing you to move data from one place (source) to another (destination).
Data pipeline management to copy data is a justifiable concern when we unpack the implications of copying data:
Cost
We are mostly talking about operational costs, knowing that storage costs have dropped drastically over the years. According to a recent survey, organizations spend on average $520,000 just to build and maintain data pipelines.
We can illustrate this high “fee” with a typical scenario: a business team is requesting access to a new customer data point in their business application — “the amount spent during the last holiday season” for each customer. What seems to just be accessing a new attribute actually requires a lot of effort: changing schemas both at the source and destination as well as adjusting the pipeline configuration itself. On top of that, any of these updates are prone to generating mistakes and breaking something.
Timelines
Any of these pipeline changes requires time to adjust, which creates friction between IT and the business as a result of lost velocity and revenue opportunities. It could take weeks to access a new customer attribute, by which time the holiday season is already gone — along with its revenue opportunities.
Security and Governance
Governments are proving themselves unforgiving when it comes to failures to respect data security and privacy regulations. Data copies spread across every application makes it extremely challenging for IT teams to keep track of and govern the data appropriately. And this only gets harder as the number of applications in the stack continues to grow.
IT is dreaming about it: what if data copy was no longer required?
Explore the Data Sharing Alternative to Data Copy
No data copy. This is a promise using the data sharing capabilities of modern data warehouses or the “data cloud,” as Snowflake calls it.
How does it work? Instead of requiring traditional file transfers via a manually created pipeline, business applications (also known as consumers) can access the data share made available by the data owner (also known as a provider).
Martech and adtech vendors started to embrace this data sharing solution, announcing partnerships and presence on data lake marketplaces.
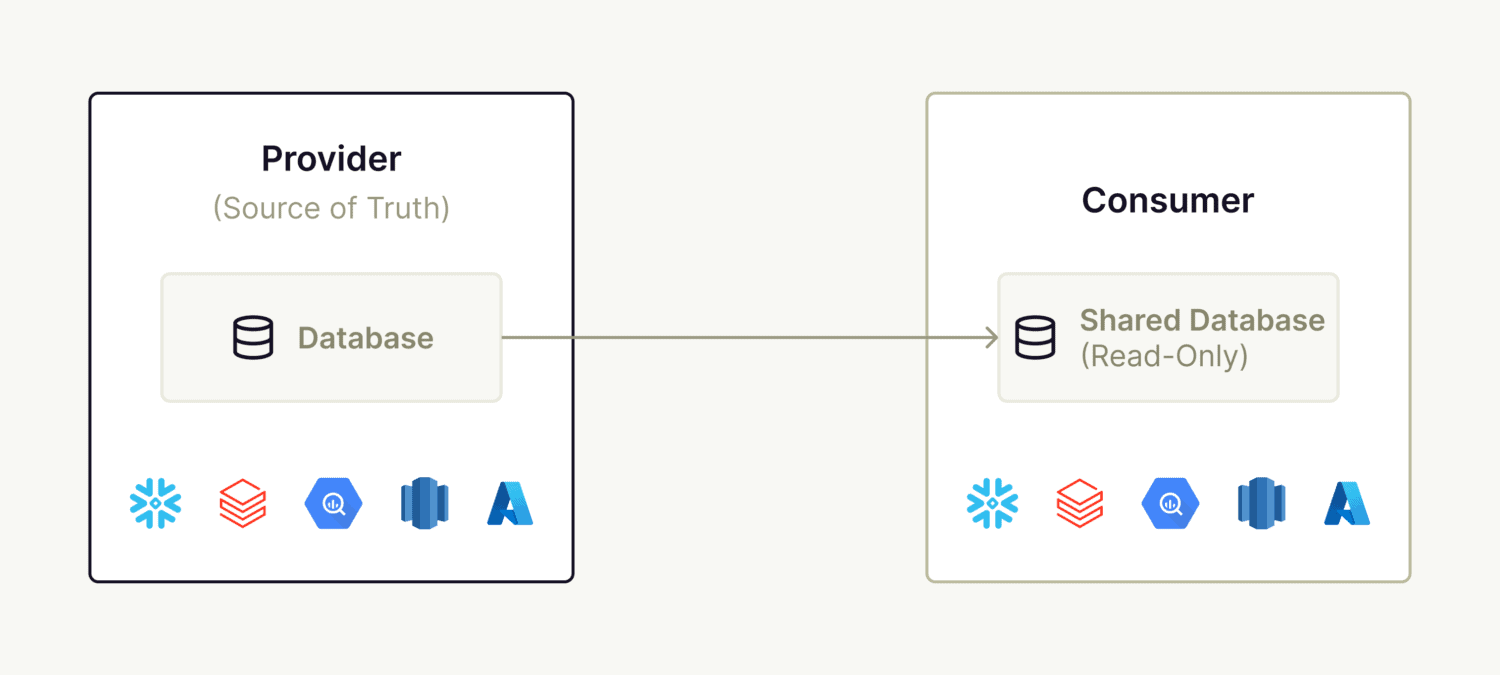
The Reality: You Are Still Copying the Data, Possibly More Than Once
If you are only looking to reduce operational costs related to data pipelines — great news — data sharing can definitely help you there. However, to be clear: Data sharing is not preventing data copy.
Let’s unpack that.
Data sharing solutions are providing a storage layer with access to data. The compute layer (e.g. execution of the query), however, is decoupled and not provided in this scenario.
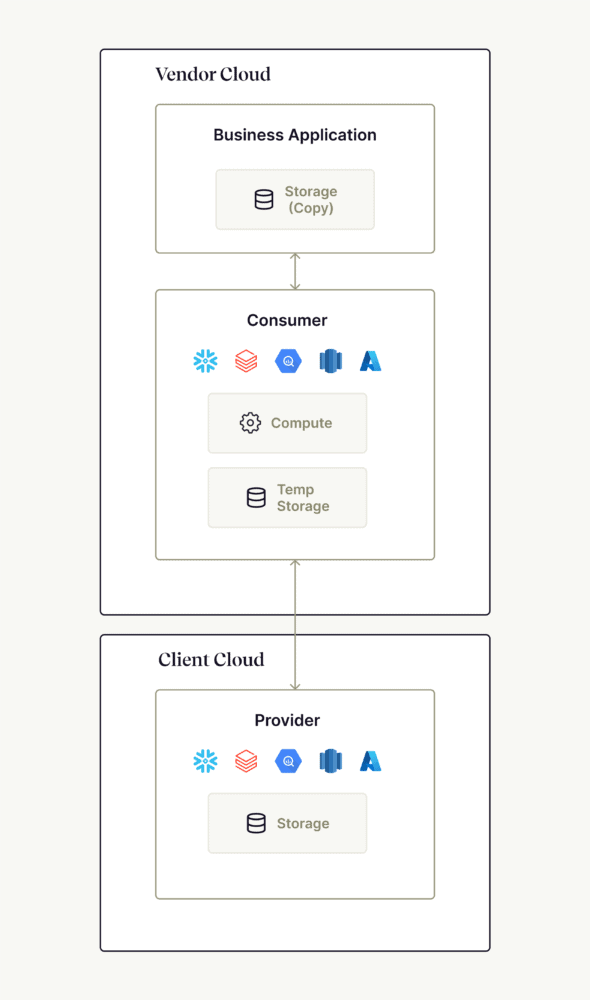
The consequence? The consumer of the data share has to deploy an environment using the same technology as the source to query the data. Translation: if you have a cloud like Snowflake, the vendor that wants to access your Snowflake data share needs to deploy itself a Snowflake environment in their cloud.
While this vendor-hosted environment won’t persist data in their Snowflake environment, they will cache it. You might argue that this cache can be refreshed frequently and the data producer can revoke access at any time, but you can’t avoid the copying of data from the source (data share) to the vendor cloud.
Things can even get messier if we go deeper. Most vendors are not natively built on the infrastructure technology you are using. For example, you might have deployed Google BigQuery as your data warehouse but the vendor is selling multiple products built on AWS. So to make their solution work, data will be copied again into those applications.
So yes, data sharing will be a great option to consider if you are concerned about minimizing data pipelines, but is definitely not a great option if your concern is preventing data copies to other vendors in your stack.
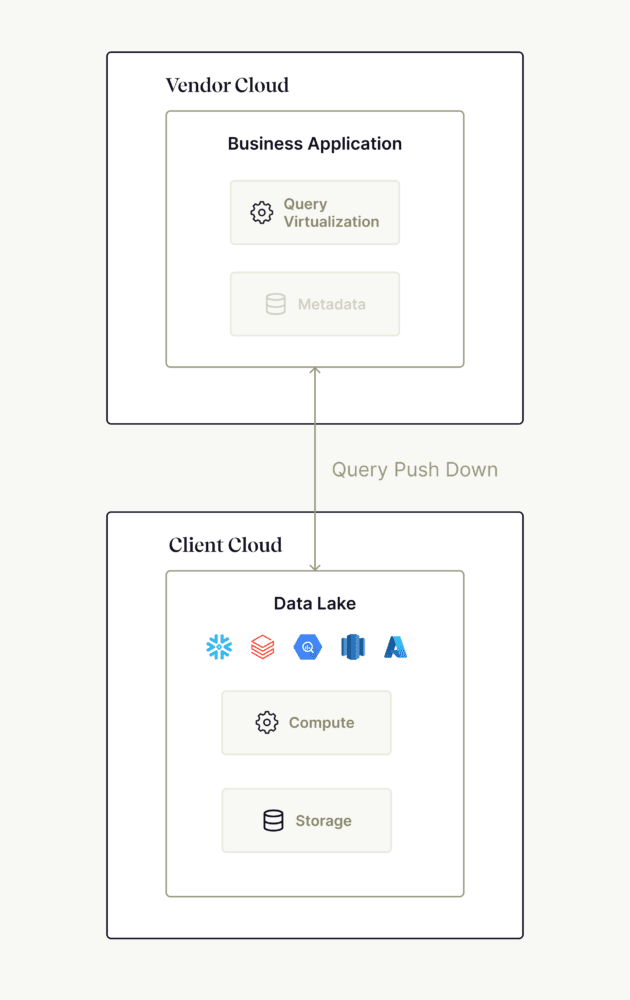
The Right Way: Query Virtualization and Push Down
Now the good news: if you are looking to achieve a true zero data copy architecture, there is a solution. That solution helps not only the brand’s cloud data lake to own the storage layer, but also the execution of business application queries. It’s providing both the fuel and the engine.
Once the application has access (access controlled by IT) to the data source, two things happen:
- Query Virtualization: The business application is translating a user action into a SQL query to be executed in step two.
- Query Push Down: The business application then pushes the generated query down to the brand’s cloud data lake, where the data is stored. The query is executed in that same environment, only surfacing back the minimal resulting data required by application.
One thing to look out for is that not every vendor offers the business user the ability to build their own segmented audiences, which burdens organizations to have IT write SQL queries. This is the opposite of what brands seek today, given the pain of IT reliance to generate audiences for the business. It’s important to carefully evaluate solutions offering you the ability to connect to your customer data warehouse.
Query virtualization and SQL query push down are the only ways that a true zero data copy architecture can be enabled. No more expensive data pipelines, and no more copies of data to manage.
How ActionIQ Enables True Zero Data Copy
With HybridCompute, a feature of ActionIQ’s purpose-built infrastructure, we provide a first-of-its-kind zero data copy architecture solution for enterprise organizations. It’s the best way to get started with a composable CDP and data stack.
Download our HybridCompute Solution Brief to learn more about how ActionIQ gives full choice and control for IT teams to build the future-proof customer data stack of their dreams. We also invite you to get in touch with our experts to learn more.

More From Our Blog

What are EDWs and how do they drive better outcomes for customers? An Enterprise Data Warehouse (EDW) is a solution that brings together all of the different stores and sources…
- Composability

For B2B marketers, it’s a new year with the same story. Customer insights are scattered across departments, and trapped in different marketing systems and tools. Marketers rely on IT and…
- Acquisition Marketing
- Composability
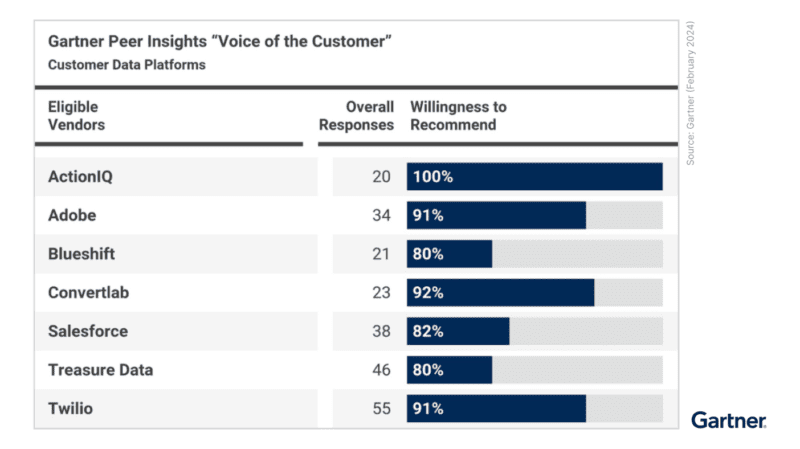
Choosing the right technology solution means understanding the real, authentic experiences of your peers. With the Gartner Voice of the Customer report, brands can do just that. The Gartner Voice…
- CDP Technologies
- Competitive Analysis
- Composability