

Why Reverse ETL is Only One Piece of the Data Puzzle

Data is the lifeblood of modern enterprises, but the average business professional likely doesn’t know what IT teams have to do to make it available to them.
Centralizing and organizing customer data in a cloud data warehouse is exacting, time-consuming work. And it’s only step one.
After creating a cloud data lake to act as the single source of truth for the business, IT professionals are tasked with getting that data out and into the hands of the teams that need it.
This is made possible via reverse ETL (rETL). But rETL on its own isn’t enough to serve the needs of both technical and non-technical teams.
Read on to understand why enterprise organizations need more than rETL to drive business success — and what IT teams can do to maximize the value of their hard work.
Why Reverse ETL is Only One Piece of the Data Puzzle
The Evolution of ETL: ETL, ELT & Reverse ETL
Before the maturation of cloud technology, IT professionals had to make do with legacy data warehouses. These technologies had very specific requirements for how data was ingested.
IT teams used to have to execute a multi-step extract, transform and load (ETL) process, pulling data from multiple sources, cleaning it, integrating it and reformatting it to be analysis-ready. Then, and only then, could data be passed into the warehouse.
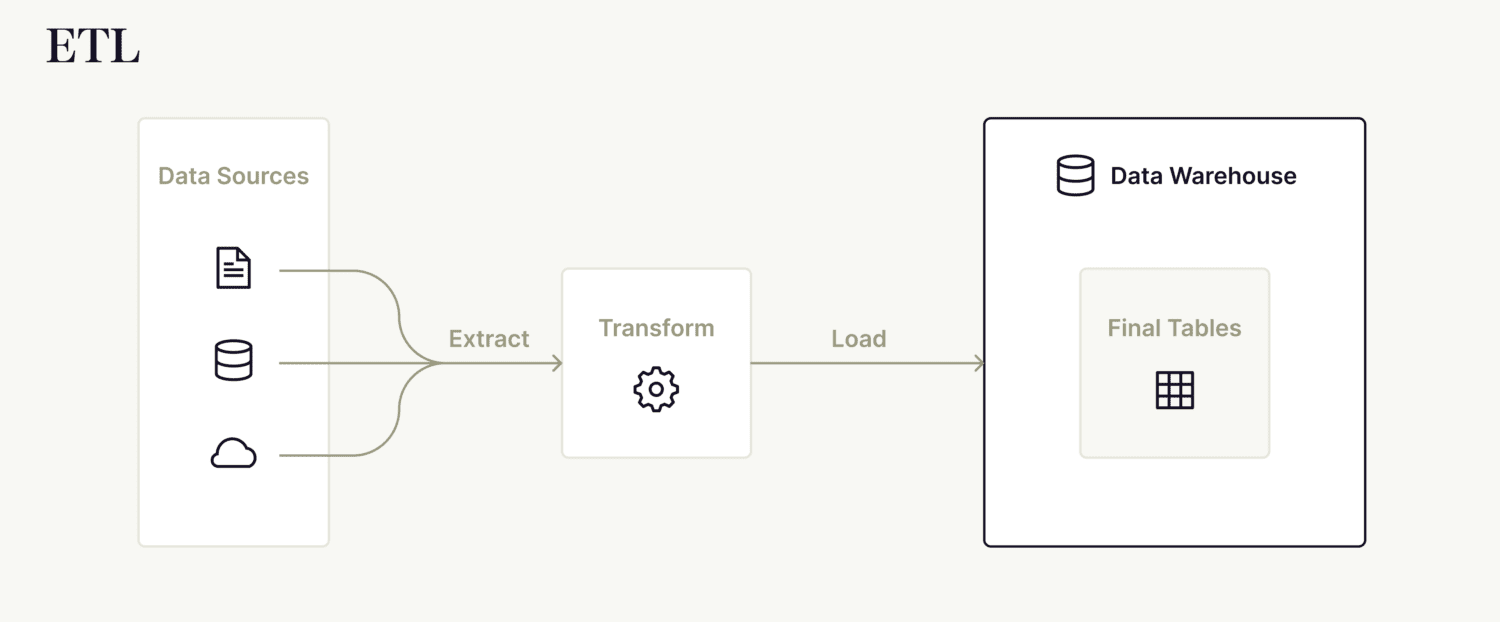
If it sounds like a headache, that’s because it was. Enter cloud data warehouses — such as Snowflake, Databricks, Google BigQuery, AWS Redshift and Microsoft Azure — and ELT.
ELT — or extract, load and transform — allows IT professionals to load data as-is into a cloud data warehouse and transform it only when it needs to be used for analysis.
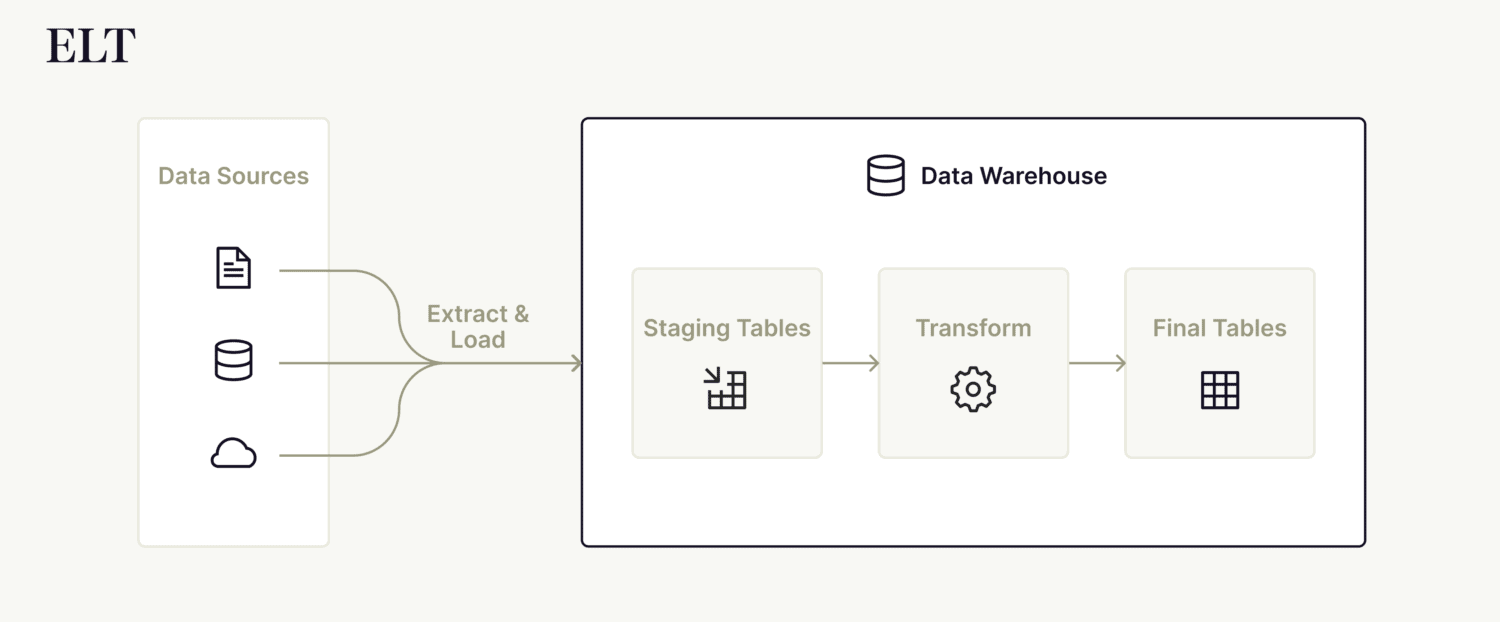
But whereas ETL and ELT are all about getting data into a warehouse, reverse ETL is about getting it out. It’s the process of taking curated data that already lives in a cloud data lake and decentralizing it once again to feed into select applications.
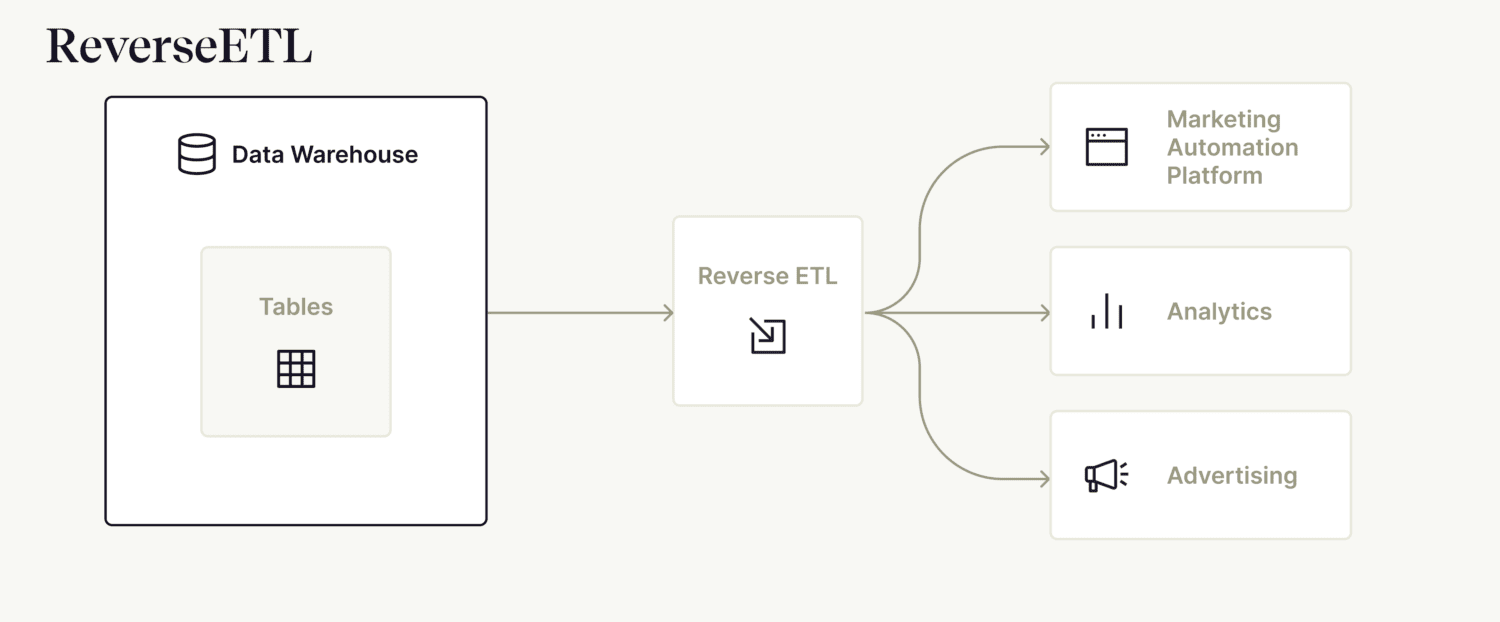
Even non-technical professionals who may have trouble explaining exactly what rETL is are starting to hear about it (the name is new, but the concept isn’t). Why? Because it’s become big business as the popularity of cloud data warehouses has exploded.
All Aboard the Reverse ETL Hype Train
As cloud technology has advanced, many organizations have extensively invested in building their own centralized data lakes — an often years-long process. In essence, this has allowed enterprise companies to eliminate the need for purchasing a prepackaged customer data platform (CDP), as they’ve created their own CDP in house. They not only have a single source of truth for customer data, but a comprehensive view of each and every customer.
Goodbye to expensive and unnecessary bundled solutions. Hello to the composable CDP and composable customer data stacks.
Thanks to reverse ETL, IT teams can push data from their homegrown customer 360 solution to the downstream systems (and teams) that need to access it. And with this freedom and flexibility has come numerous vendors that exclusively provide rETL capabilities. These emerging players are banging the rETL drum and positioning it as the be-all and end-all of modern data operations.
Deploying a vendor’s rETL solution is certainly the easiest and quickest way to get data out of a data lake. But these vendors fail to mention how rETL by itself falls short of everything enterprise companies need to drive efficiency, revenue and better, personalized customer experience (CX).
Intelligence Silos and Gaps Persist
Reverse ETL is only focused on getting data out of the cloud data lake — and without the right tools in place, this can lead to multiple challenges.
When data is passed to applications via rETL, it’s replicated within the app and enriched with new signals specific to it. This data doesn’t make its way back to the cloud data lake, creating the type of data silo IT professionals have spent years trying to get rid of.
The business teams using these apps no longer benefit from the single source of truth IT teams created. And the problem is compounded by the fact that most organizations use best-of-breed solutions for every individual channel, exponentially increasing the number of apps and data silos. That means teams miss out on centralized customer intelligence.
There’s also the problem of real-time data. While cloud data warehouses can be used to collect the entire history of a customer’s interaction with a brand via batch ingestion, it struggles to do the same for real-time, in-the-moment actions. That’s because these technologies are not built to support real-time workloads and use cases. A different customer data infrastructure is required.
And in a world where customers expect brands to anticipate their needs and deliver the right experience at the exact right time, this puts organizations at a serious disadvantage.
Discover the Best of Both Worlds
Prepackaged CDPs that force IT professionals to bend to their restrictive system architectures are on their way out. Composable architecture powered by cloud data lakes are the future.
But reverse ETL isn’t enough on its own to help IT teams make the most of their investments.
Organizations must invest in rETL solutions that eliminate data silos while also serving as an infrastructure for real-time workloads.
With a CX hub built on top of a cloud data lake, non-technical users can access the customer data they need using a business-friendly UI that automatically translates their actions into SQL queries. And IT professionals can maintain control of customer data by deciding where it lives and is queried to support their customer data security, governance and cost management goals.
It’s a win-win for IT professionals, their colleagues and, ultimately, customers.
IT teams have put their figurative blood, sweat and tears into centralizing and organizing customer data. Whichever rETL solution they use to extract value from it, it shouldn’t come at the cost of their hard work.
Learn More About Reverse ETL
Download The Enterprise Guide to Composable CDPs to learn how you can build a better customer data stack using the AIQ CX Hub.

Featured Posts
More From Our Blog

What are EDWs and how do they drive better outcomes for customers? An Enterprise Data Warehouse (EDW) is a solution that brings together all of the different stores and sources…
- Composability

For B2B marketers, it’s a new year with the same story. Customer insights are scattered across departments, and trapped in different marketing systems and tools. Marketers rely on IT and…
- Acquisition Marketing
- Composability
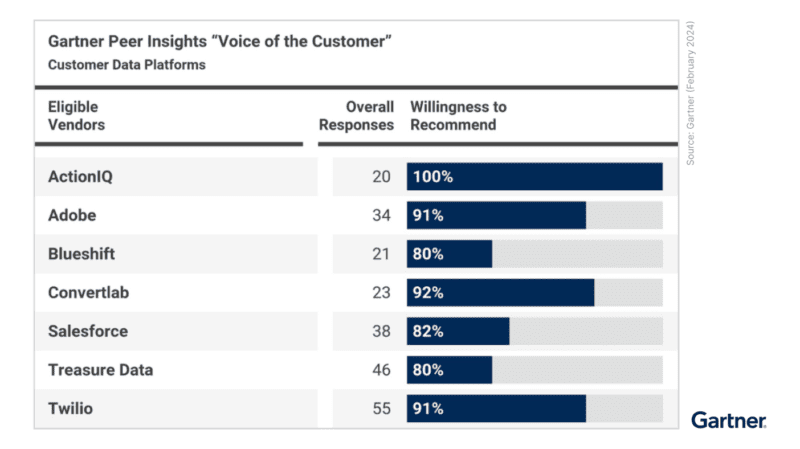
Choosing the right technology solution means understanding the real, authentic experiences of your peers. With the Gartner Voice of the Customer report, brands can do just that. The Gartner Voice…
- CDP Technologies
- Competitive Analysis
- Composability